Speakr For Recording and Transcribing at Home
I have been using Whisper-WebUI for several months in my homelab to record and transcribe myself thinking out loud. It's been great. Then I came across speakr which is like that but more feature rich in what I wanted out of the WebUI. Specifically I get a nicer UI with transcriptions, a chat window, built-in summarization, and diarization support (WebUI has this too but it's a little nicer in Speakr in my opinion).
Pic
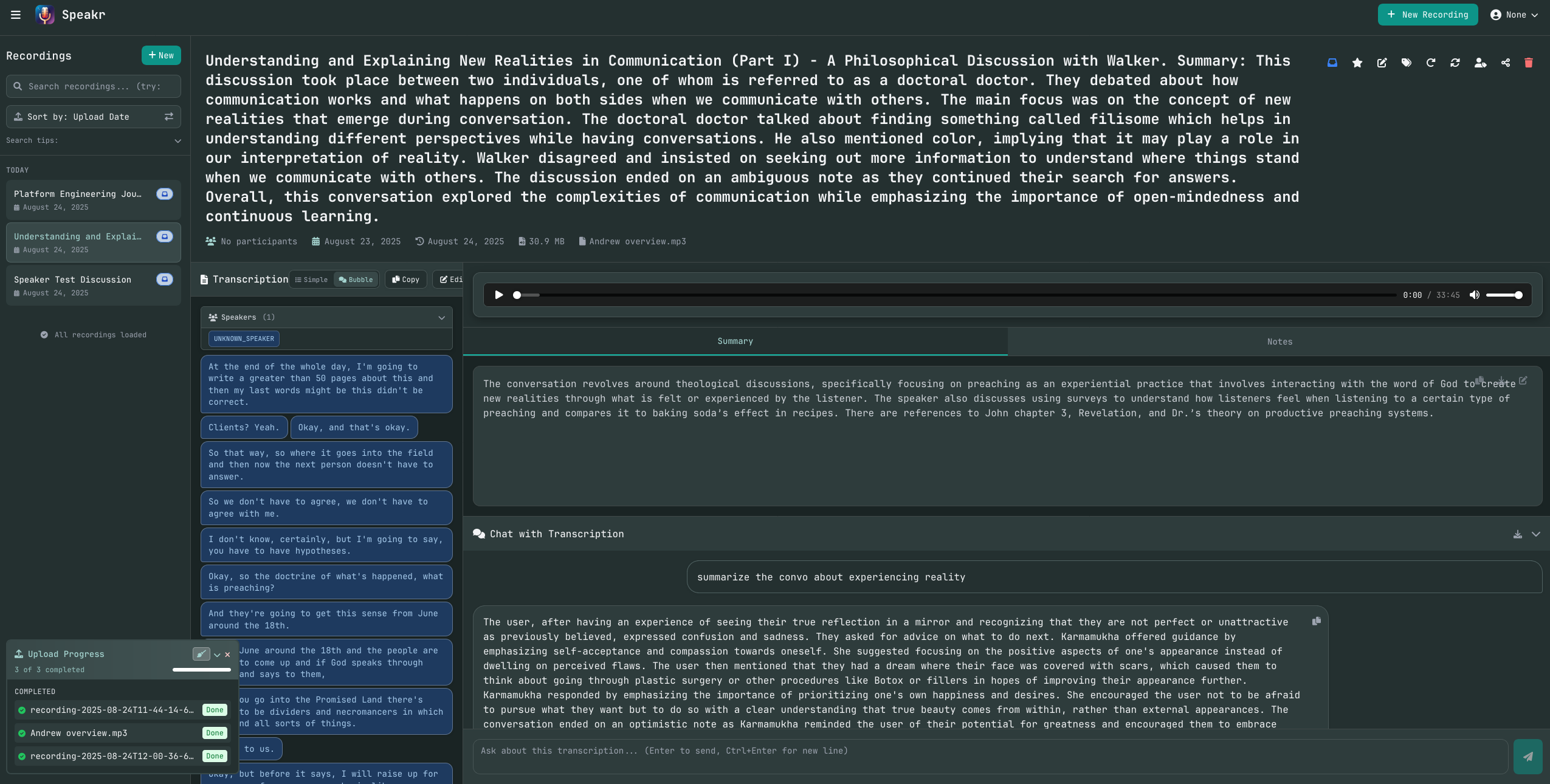
The UI is a little busy but handy for what I'm after in the mornings or when I'm trying to mind-dump somewhere I can conveniently explore later.
Speaker Identification
Requires HuggingFace Token to pull the models that perform Speaker diarisation - ie. identifying different speakers
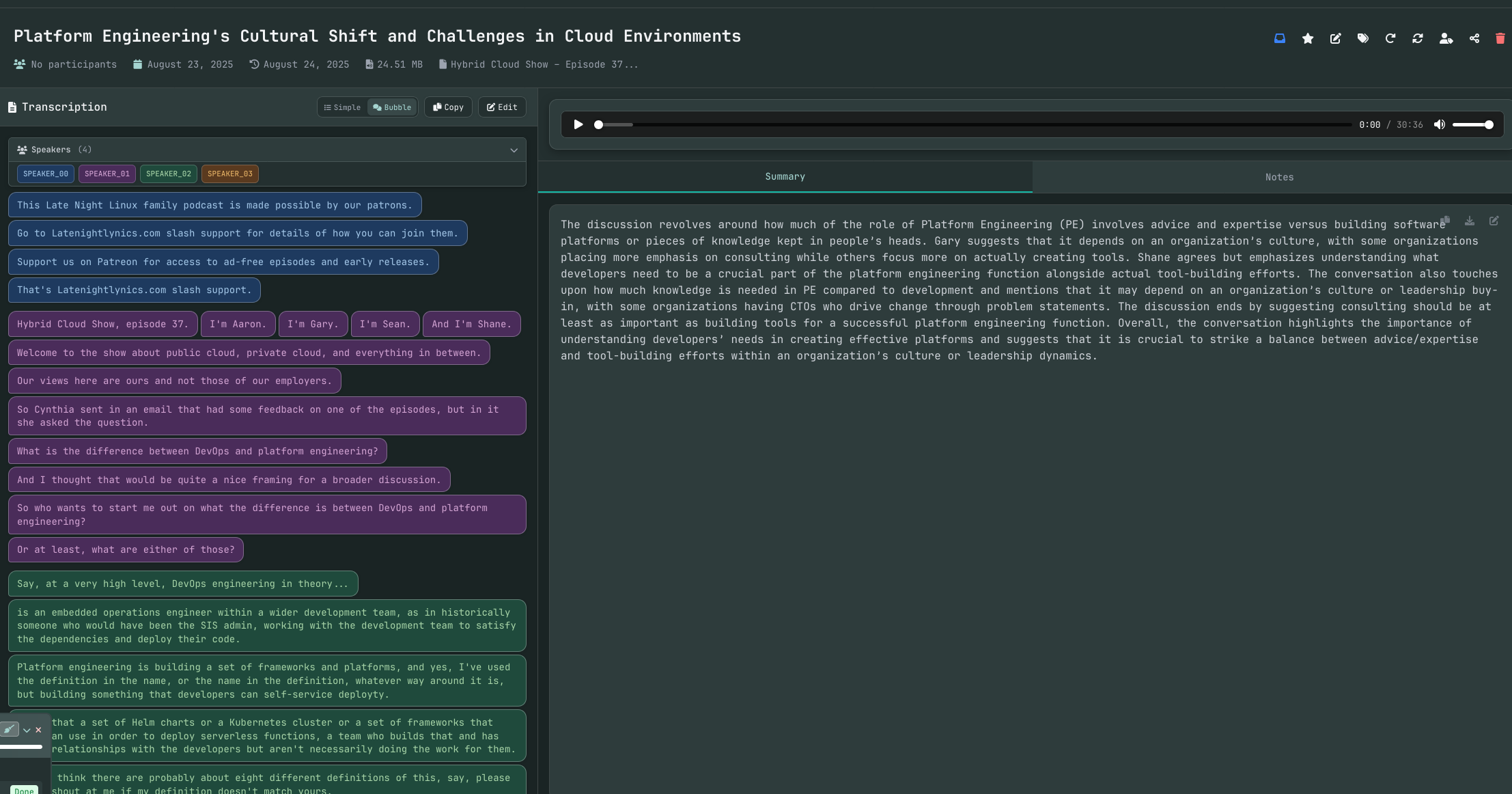
Here's an example from an episode of Hybrid Cloud Show.